🔎Using Single Point of Failure Analysis to reduce the Risk of Outages on Business Critical Services in South African Data Centres 🇿🇦
Discover How Single Point of Failure Analysis Can Prevent Outages in South African Data Centres

Driving SD-WAN Adoption in South Africa
MyBroadband highlighted the problem related to single points of failure in South African data centres following a recent event in the Teraco – A Digital Realty Company datacentre in Durban:
In this case, Openserve deflected any responsibility and never answered the most pertinent questions related to the incident:
Was Openserve kit deployed using dual power supplies and connected to both the A and B feed from the datacentre?
Did any Openserve kit that only had a single power supply and that was connected to the A feed, have a redundant functional unit connected to the B feed?
Did Openserve subscribe to sufficient power when using just a single feed to maintain the functionality of their Point of Prescense (POP)?
Did Openservice test the continuity of their kit and POP by simulating failures of the A and B feed? Is Openserve going to fail again on the next power maintenance?
Datacentres provides power with a maximum draw available per feed to a rack. The responsibility for power management is the responsibility of the rack owner who needs to ensure that the power draw remains within limits for each feed. If we investigate the scenario where a rack has servers, switches and routers on dual power paths, but were on the limits or near their limits for each power feed we will deduce an obvious problem. When a power feed goes down (as in the case of maintenance), the other power feed will be over the limits resulting in a trip. The causation in this case is thus squarely the responsibility of the rack owner.
Additional example of Single Point of Failures
On 26 November 2024 Seacom experienced an outage in Johannesburg when their equipment overheated due to a faulty fan tray. The effected router was a single point of failure as there was no alternative fail-over network path available should that unit fail.
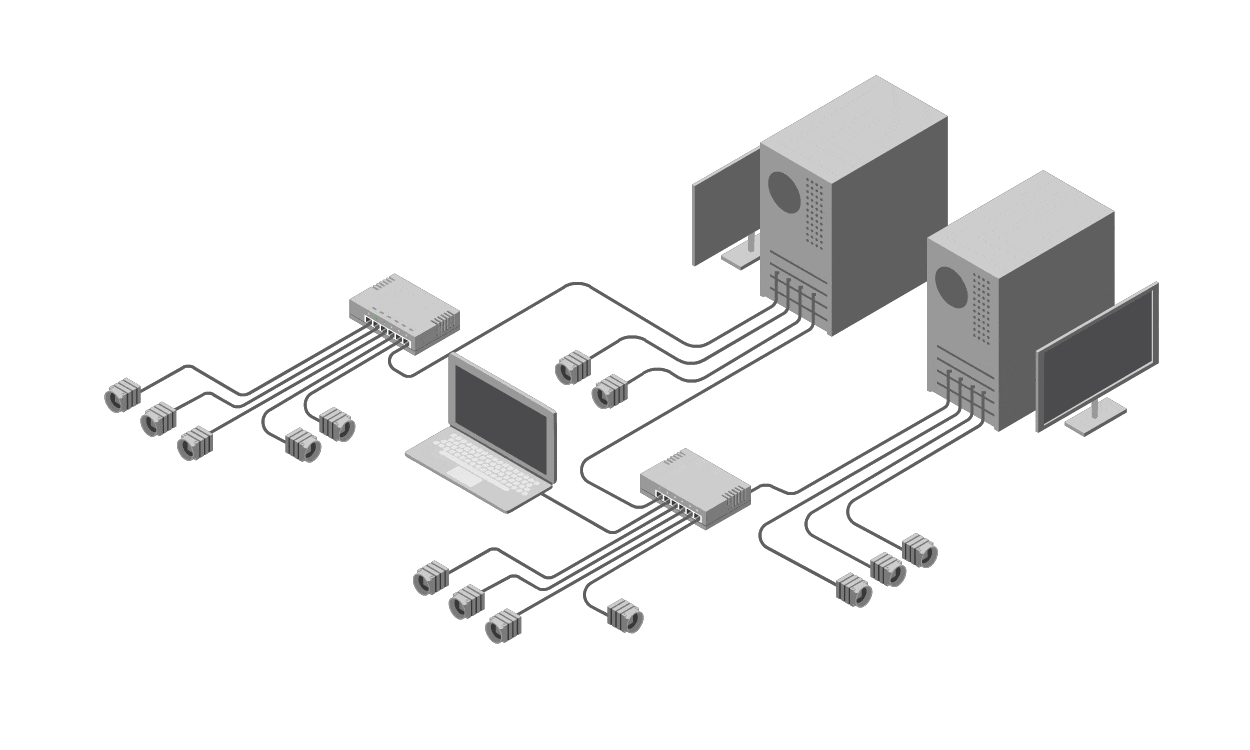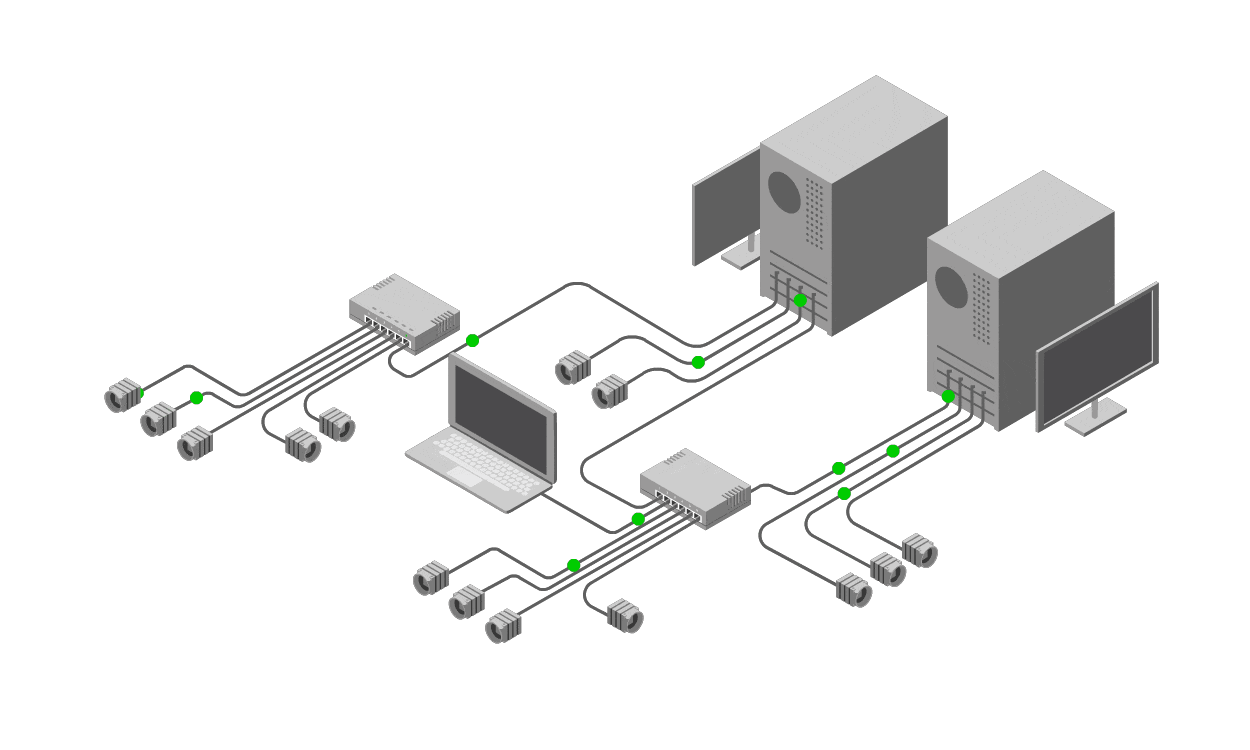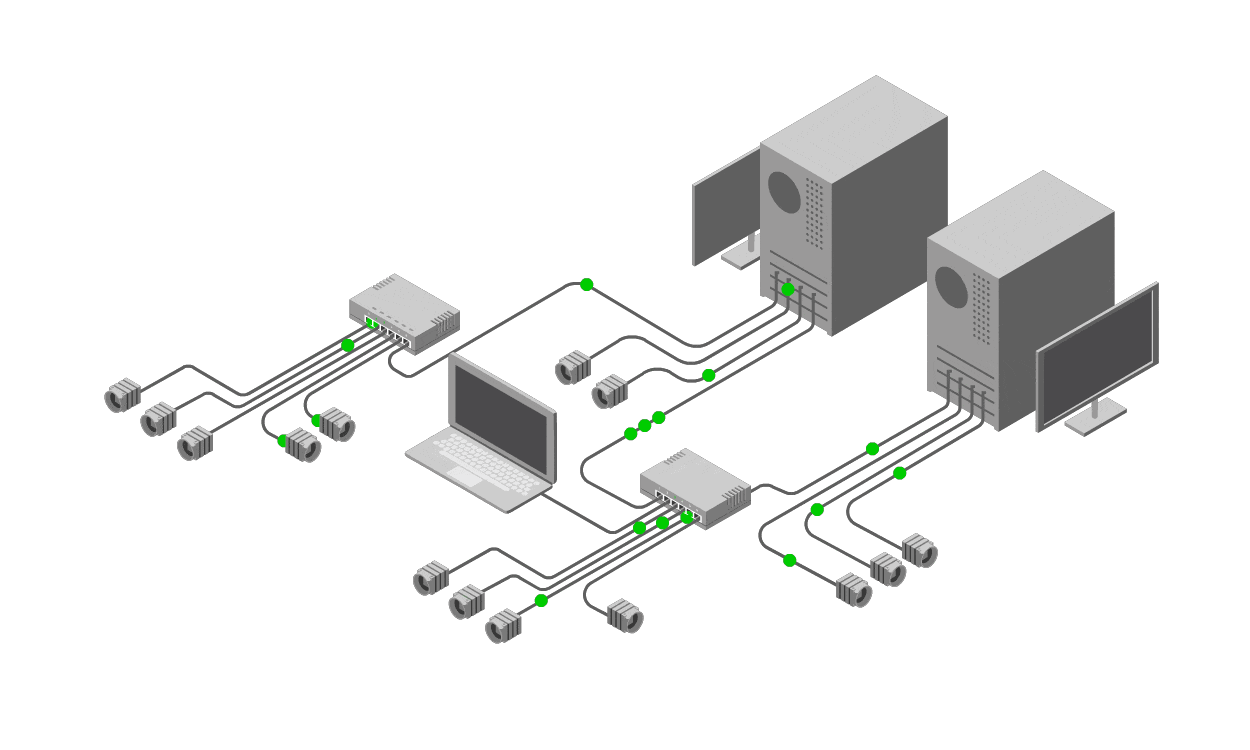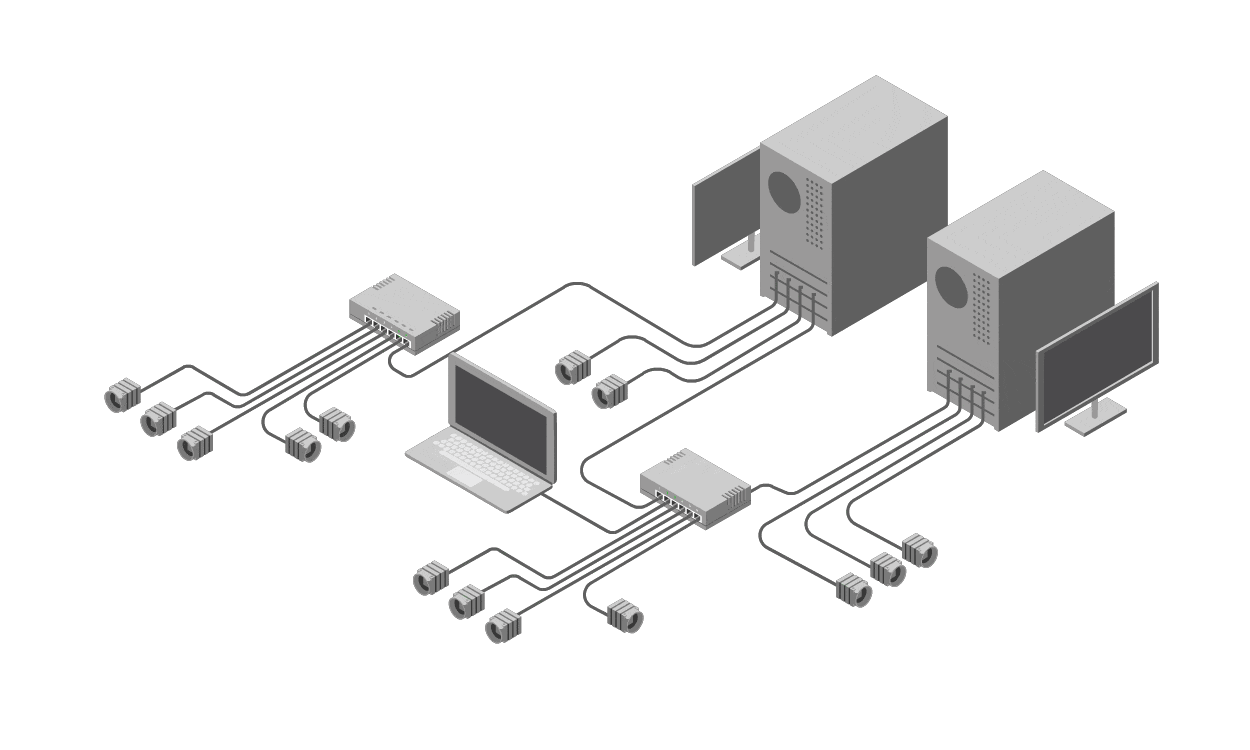
Single Point of Failure Analysis
There are 3 suggested processes that can be used by an owner of a rack in a data centre to determine reliability of which a Single Point of Failure Analysis process is one. In the some Information Technology process frameworks this process is made up of a Service catalogue, Business Impact Assessment and Component Failure Impact Analysis. The process detailed here would obviously benefit a rack owner such as Openserve.
It is not sufficient to look at the physical layer and make a determination as significant number of service are being abstracted and delivered in a virtualization fashion. It cannot be assumed that the configuration of the virtual infrastructure is resilient and neither can it be assumed that all services are being delivered in a generic fashion.
The process involves first creating a service catalogue. This catalogue lists the consumed services including applications and their dependencies of what is being used in the datacentre. Next these service are categorized via a business impact assessment. This will provide input into the level of resilience each application requires. Finally there is the component failure impact analysis as the last step. These 3 steps constitute an appropriate analysis of single points of failure.
The following links provide overviews to the above processes and are sourced from ITSM Solution from 2009 but still perfectly relevant.
Service Catalogue
Business Impact Assessment
Component Impact Failure Analysis
Ronald Bartels ensures that Internet inhabiting things are connected reliably online at Nepean Networks - the leading specialized SD-WAN provider in South Africa. Learn more about the best SD-WAN in the world: 👉Contact Nepean🚀
Read how Nepean Networks provides mitigations against last mile single points of failure: