The Pitfalls of Inadequate Evidence in Networking Tickets
Why Pings Aren't Enough & NMS is Essential

Driving SD-WAN Adoption in South Africa
In network operations, troubleshooting issues is a daily reality. Whether it's a sudden outage, intermittent connectivity problems, or performance degradation, operators and support teams rely on tickets and escalations to document and resolve these challenges. However, a persistent problem plagues this process: the lack of suitable evidence provided by many operators. All too often, the "proof" submitted boils down to a brief ping test—perhaps a few seconds of latency checks or packet loss data. While pings have their place in basic diagnostics, they fall woefully short for complex, time-sensitive networking trends or telemetry analysis. This approach is insufficient, and the rationale is to rather implement a robust Network Management System (NMS), which will elevate service quality to new heights.
The Limitations of Ping-Based Evidence
Ping, or Internet Control Message Protocol (ICMP) echo requests, is a simple tool that's been a staple in networking since the 1980s. It sends packets to a destination and measures round-trip time, packet loss, and reachability. In tickets and escalations, operators frequently attach screenshots or logs of these short ping sessions as evidence of an issue. But here's the rub: if the problem occurred an hour ago, was fleeting, or is intermittent, a current ping test is about as useful as checking the weather after a storm has passed.
Consider a scenario where a user reports intermittent packet drops on a critical link. The operator runs a quick ping from their end, sees no issues in those 10-20 seconds, and closes the ticket with "no fault found." Meanwhile, the root cause—perhaps a flapping interface, congestion during peak hours, or a misconfigured Quality of Service (QoS) policy—remains undetected because the evidence doesn't capture the historical or contextual data. Intermittent problems, by definition, don't manifest consistently; they might spike during high traffic, specific times of day, or under certain load conditions. A snapshot ping ignores these dynamics, leading to prolonged downtime, frustrated customers, and repeated escalations.
This short-sighted approach not only delays resolution but also erodes trust. Customers expect operators to provide comprehensive diagnostics, not superficial checks. In industries like telecommunications, finance, or healthcare, where network reliability is paramount, such oversights can result in significant financial losses or operational risks.
The Rationale for a Proper Network Management System (NMS)
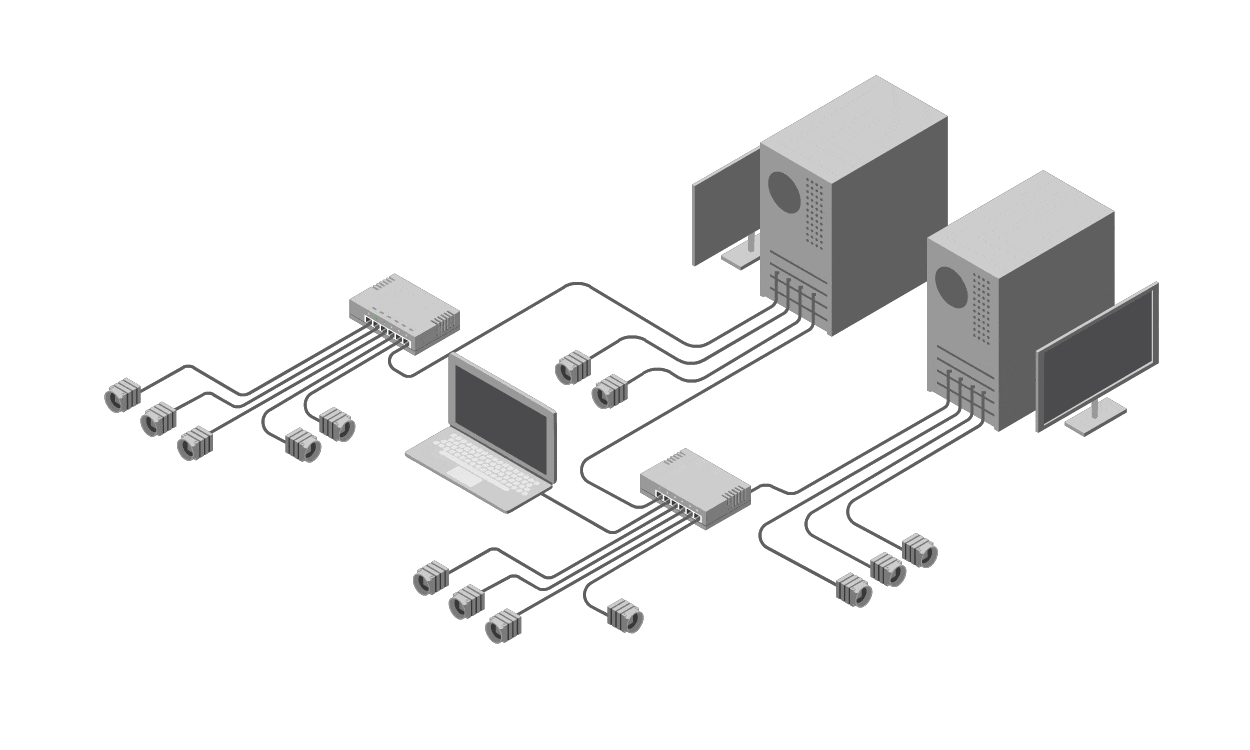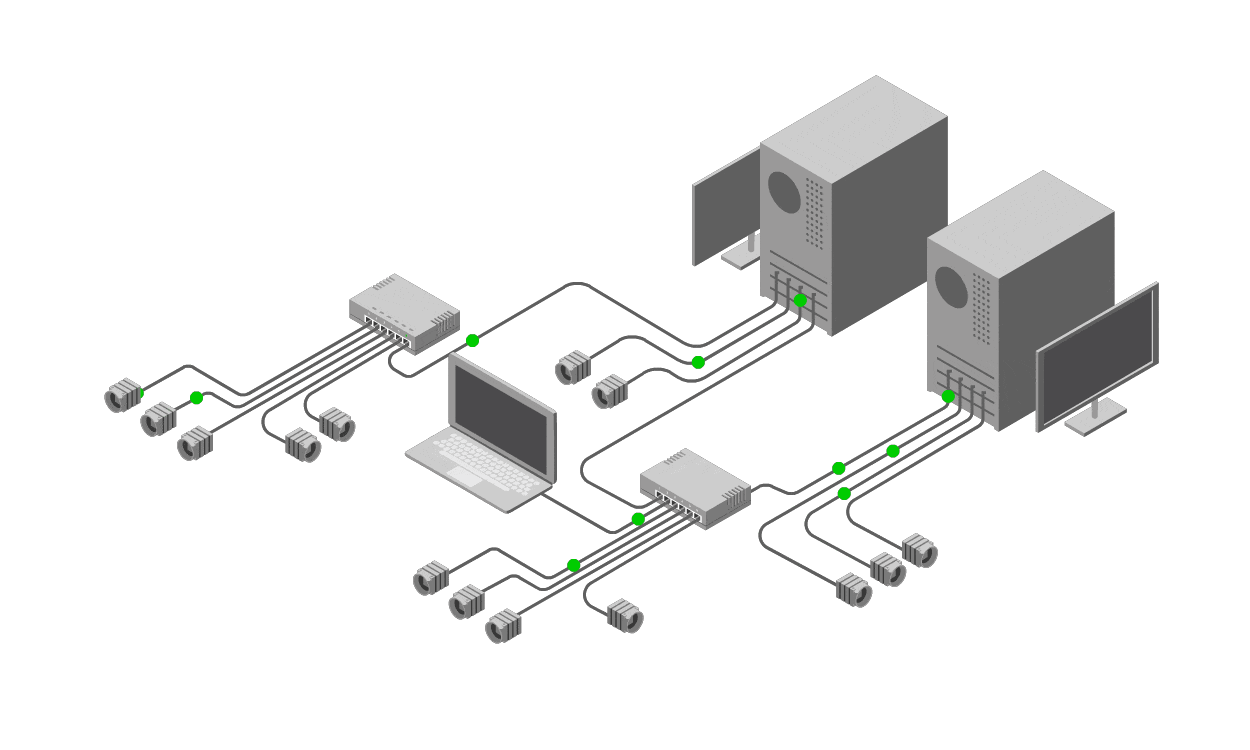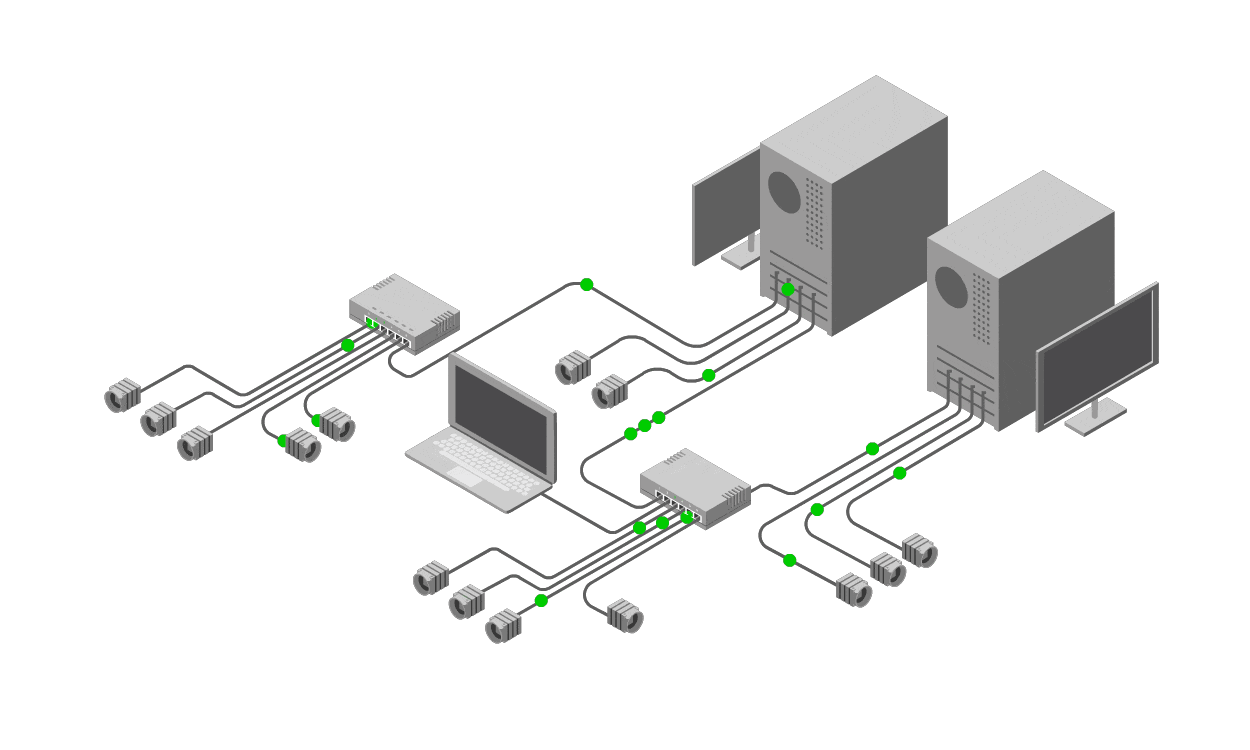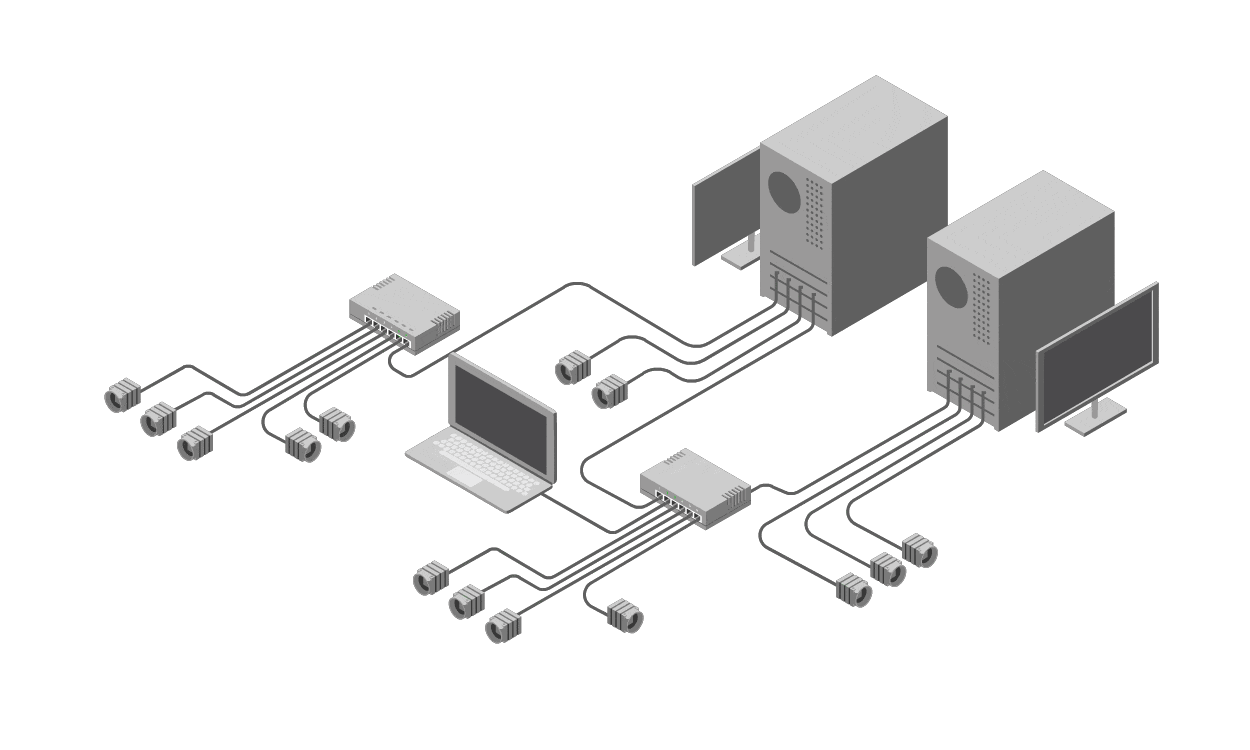
To address these shortcomings, operators need to shift from reactive, ad-hoc tools like ping to a proactive, holistic solution: a Network Management System (NMS). An NMS is a centralized software platform designed to monitor, manage, and analyze network devices, links, and performance in real-time and over extended periods. It goes beyond basic reachability tests by collecting and correlating a wide array of telemetry data from across the network.
At its core, an NMS operates on the principle of comprehensive visibility. It aggregates metrics from both sides of a link—source and destination—ensuring a balanced view rather than a one-sided ping. Key components include:
Performance Metrics Collection: NMS tools track not just latency and packet loss (like ping) but a full suite of indicators, such as bandwidth utilization, error rates, jitter, throughput, CPU/memory usage on devices, and signal-to-noise ratios in wireless or optical links. This data is gathered continuously from routers, switches, firewalls, and other infrastructure elements.
Historical and Trend Analysis: Unlike a momentary ping, an NMS stores data over days, weeks, or months. It allows operators to collate information over extended time periods, identifying patterns like recurring spikes in latency every evening or gradual degradation in link quality. Tools like time-series databases (e.g., InfluxDB) or built-in graphing capabilities enable visualization of trends, making it easier to spot anomalies.
Correlation Across Layers: Networks are multi-layered (physical, data link, network, etc.), and issues often span them. An NMS correlates data from various sources—SNMP polls, NetFlow/sFlow exports, syslog events, and even API integrations with cloud services—to provide a unified view. For instance, if a ping shows loss, the NMS might reveal it's due to a upstream router's high CPU from a DDoS attack, not the link itself.
Alerting and Automation: Proactive monitoring means setting thresholds for metrics (e.g., alert if jitter exceeds 30ms for more than 5 minutes). This rationale emphasizes prevention over cure, catching issues before they escalate into full-blown outages.
The underlying rationale for an NMS is rooted in the complexity of modern networks. With the rise of SD-WAN, IoT devices, 5G, and hybrid cloud environments, relying on manual pings is akin to navigating a city with a compass but no map. An NMS provides the "map"—a dashboard of insights that ensures decisions are data-driven, not guesswork.
How NMS Enhances Service Quality
Implementing a proper NMS transforms network operations from firefighting to strategic management, ultimately delivering better service to end-users. Here's how:
Faster Issue Resolution: With collated data over time, operators can quickly pinpoint root causes. For example, in a ticket for intermittent VoIP quality issues, an NMS might show correlated spikes in jitter and bandwidth usage during video calls, leading to targeted fixes like QoS adjustments. This reduces mean time to resolution (MTTR) and minimizes escalations.
Proactive Maintenance: By analyzing trends, NMS enables predictive analytics. Operators can forecast potential failures—such as a link approaching capacity—and intervene early. This shifts the paradigm from reactive support to preventive care, improving uptime and customer satisfaction.
Comprehensive Evidence in Tickets: When escalating issues, NMS-generated reports provide irrefutable evidence: graphs of metrics over hours or days, anomaly detections, and cross-link comparisons. This fosters collaboration between teams (e.g., NOC and engineering) and builds credibility with customers, who can see the full picture rather than dismissing a "clean" ping.
Cost Efficiency and Scalability: Automating monitoring reduces manual labor, allowing operators to handle more tickets efficiently. For large-scale networks, NMS scales to thousands of devices, integrating with tools like Zabbix, Nagios, or SolarWinds for customized workflows.
Improved Compliance and Reporting: In regulated sectors, NMS logs ensure audit trails for performance SLAs. Customers receive detailed service reports, reinforcing trust and enabling data-backed negotiations for upgrades.
Real-world examples abound: Mature telecommunications operators use NMS platforms to monitor links, collating metrics from submarine cables to terrestrial routers, preventing outages that could affect customers.
Wrap | Embracing NMS for a Resilient Future
The era of submitting a few seconds of ping as "evidence" in networking tickets must end. It's a relic that ignores the intermittent, historical, and multifaceted nature of modern network issues. By adopting a robust NMS, operators gain the tools to monitor full performance metrics across links, over meaningful timeframes, and with deep correlation. This not only rationalizes diagnostics but also elevates service delivery—turning potential disasters into manageable insights. For network professionals, investing in NMS isn't just best practice; it's a necessity for staying ahead in an increasingly connected world. Operators who make this shift will find themselves resolving issues faster, delighting customers, and building networks that are as reliable as they are innovative.

Ronald Bartels | LinkedIn | Instagram