The Pitfalls of Process of Elimination in Troubleshooting
Embracing First Principles & the Scientific Method

Driving SD-WAN Adoption in South Africa
In the area of information technology, where systems grow increasingly complex, troubleshooting remains a critical skill. Yet, many IT professionals and hobbyists alike fall back on simplistic methods like the process of elimination, often leading to inefficiency, frustration, and even new problems. This article explores why relying on process of elimination is often inappropriate for troubleshooting, distinguishes it from mathematical concepts like negation or proof by contradiction, and advocates for a more rigorous approach rooted in first principles, evidence gathering, and the scientific method. We'll pay special attention to its application in computer networking, where interconnected systems amplify the risks of flawed methodologies.
Understanding the Process of Elimination in Troubleshooting
The process of elimination in troubleshooting typically involves systematically ruling out potential causes of a problem by testing or disabling components one by one. For instance, if a network connection fails, you might unplug cables, restart devices, or disable software features sequentially until the issue resolves. At first glance, this seems logical—like checking off items on a checklist. However, in complex systems, this method is often inappropriate and inefficient.
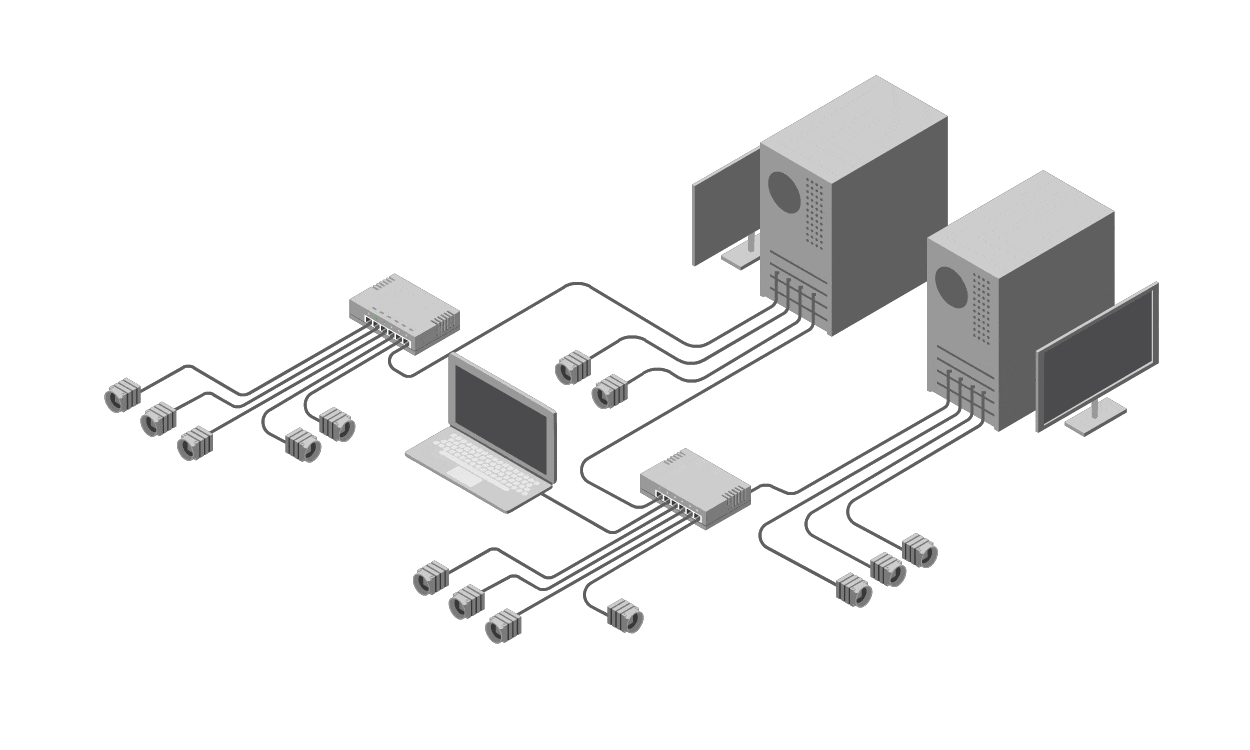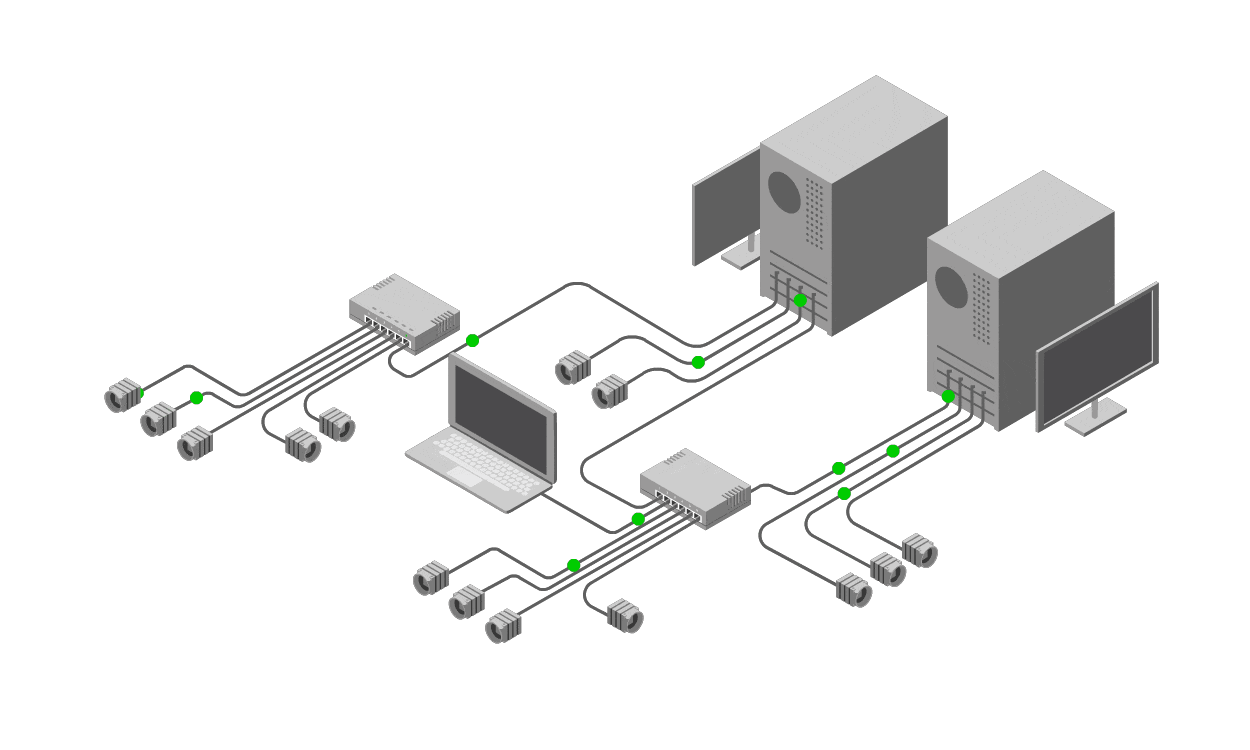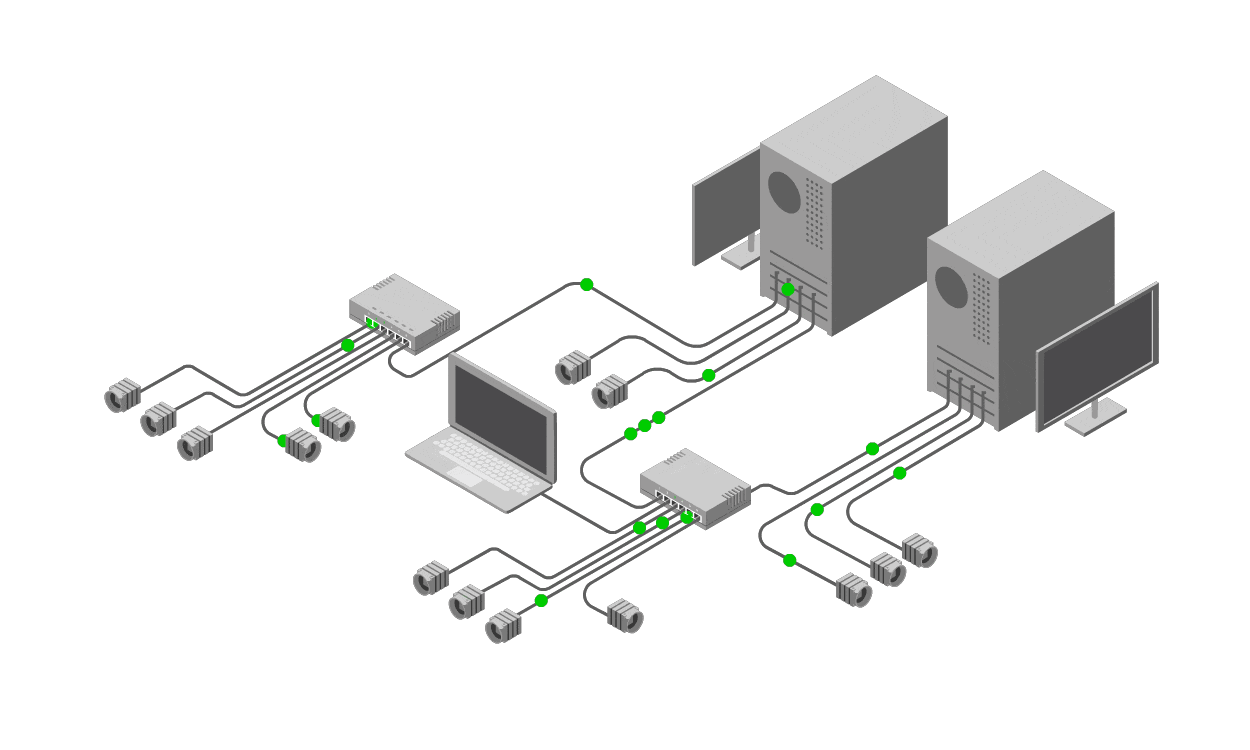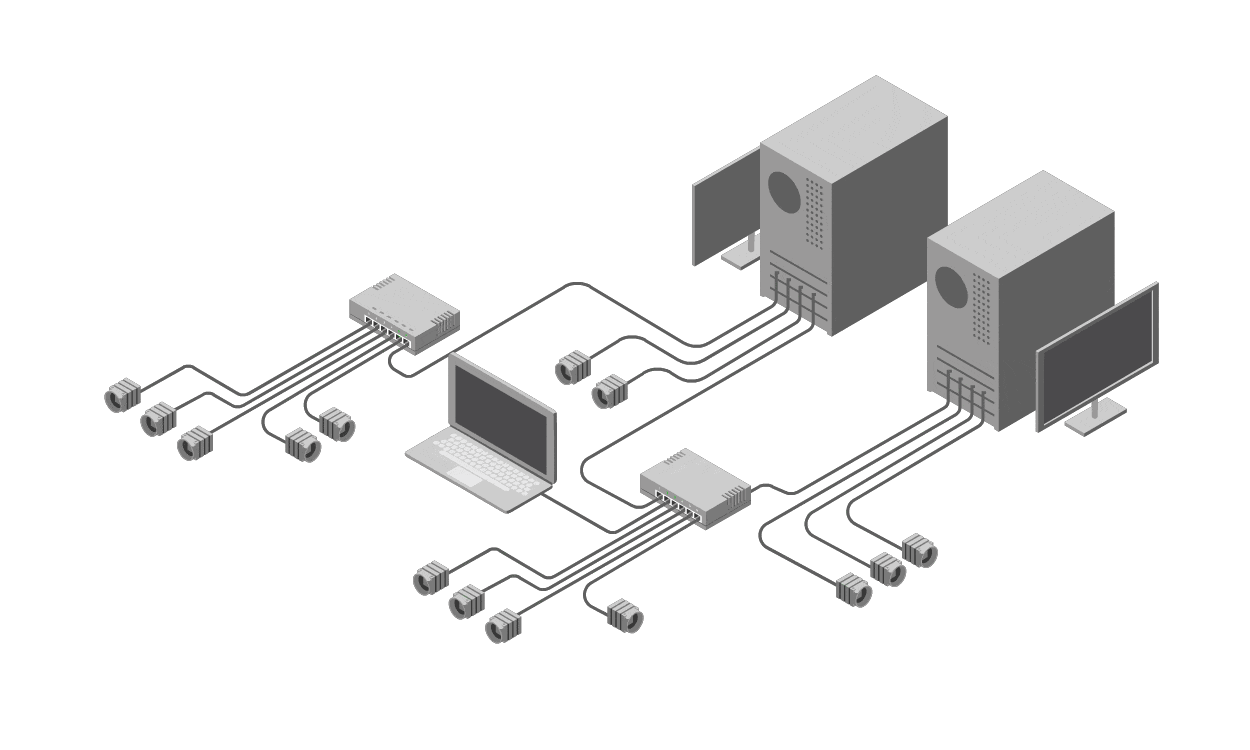
Why? Complex IT environments, such as modern computer networks, involve interdependent components: hardware, software, configurations, and external factors like power supply or environmental interference. Eliminating variables haphazardly can waste time, as the sheer number of possibilities explodes combinatorially. More critically, it's risky. Each intervention—say, rebooting a server or altering a configuration—carries the potential to introduce new failures. A simple restart might corrupt data in transit, or disabling a firewall could expose the system to security threats. Instead of isolating the root cause, you might create a cascade of issues, turning a minor glitch into a major outage.
This risk is amplified in production environments, where downtime costs money and erodes trust. Troubleshooting via elimination doesn't build understanding; it merely hopes to stumble upon a fix. And if it fails? You're left with a system that's been poked and prodded, potentially in a worse state, without any new insights.
Distinguishing from Mathematical Negation
A common misconception is equating troubleshooting's process of elimination with mathematical negation or proof by contradiction. These are not the same, and understanding the difference highlights why the former falls short.
In mathematics, negation involves denying a statement to explore its implications. Proof by contradiction assumes the opposite of what you're trying to prove and shows it leads to an absurdity, thereby affirming the original statement. This is a deductive, logical process grounded in axioms and evidence. For example, to prove that √2 is irrational, you assume it's rational and derive a contradiction.
Troubleshooting's process of elimination, however, is often inductive and empirical but lacks the rigor. It's more like trial-and-error: you negate (or eliminate) possibilities without a structured hypothesis or comprehensive evidence. Mathematical negation builds on first principles—fundamental truths—and uses logic to eliminate impossibilities systematically. In contrast, IT elimination is reactive, not proactive; it doesn't start from axioms like "the system should behave this way based on its design." It risks overlooking interactions between variables, leading to false negatives or incomplete resolutions.
The key difference? Mathematics demands proof and reproducibility; troubleshooting elimination often settles for "it works now," without explaining why.
The Better Path | First Principles & Evidence-Based Troubleshooting
Effective troubleshooting requires moving beyond elimination to first principles: breaking down the problem to its fundamental truths. Ask: What is the system's expected behavior? What is the observed (known) behavior? This contrast forms the foundation for diagnosis.
Expected behavior is derived from design specifications, documentation, and standards. For a web server, it might include responding to HTTP requests within milliseconds under normal load. Known behavior is what you're observing—e.g., intermittent timeouts. The gap between them points to anomalies.
From here, obtain evidence through targeted observation and testing. Use tools like logs, monitoring software, or diagnostic commands to gather data without disrupting the system. This evidence-driven approach minimizes risks and builds a verifiable path to resolution.
One of the worst curses in troubleshooting exemplifies the pitfalls: "Turn it off and on again." This reboot mantra sometimes works by clearing transient states like memory leaks or hung processes. But what if it doesn't? You've reset the system without learning anything. Worse, in complex setups, reboots can mask symptoms (e.g., a failing hard drive that survives one more cycle) or exacerbate issues (e.g., interrupting a database transaction). It's a band-aid, not a cure, and it discourages deeper analysis.
Applying the Scientific Method in Information Technology
The scientific method offers a structured alternative, transforming troubleshooting from guesswork to a disciplined process. It involves observation, hypothesis formation, experimentation, analysis, and iteration—perfectly suited to IT, where systems are testable and measurable.
In computer networking, where issues like packet loss, latency, or routing failures are common, the scientific method shines. Here's how it applies:
Observation and Question: Start by documenting the problem precisely. In networking, use tools like ping, traceroute, or Wireshark to observe symptoms. For example, if users report slow internet, note: "Latency spikes to 500ms during peak hours, but bandwidth tests show full speed."
Research and Hypothesis: Draw on first principles—network fundamentals like OSI layers, TCP/IP protocols, and hardware specs. Form a testable hypothesis: "The issue is due to congestion at the router level (Layer 3), not cabling (Layer 1)."
Experimentation: Design low-risk tests to gather evidence. In networking, this might involve monitoring traffic with SNMP, checking switch logs, or simulating load with tools like iPerf. Avoid broad eliminations; instead, isolate variables methodically, such as temporarily rerouting traffic to test a hypothesis without full system disruption.
Analysis: Compare results against expected behavior. If the hypothesis holds (e.g., router CPU spikes correlate with latency), proceed to resolution. If not, refine it—perhaps it's DNS resolution failing under load.
Conclusion and Iteration: Implement fixes, verify, and document. If the problem recurs, iterate. This builds institutional knowledge, preventing future issues.
In networking, complexity arises from distributed systems: firewalls, VLANs, BGP routing, and cloud integrations. Process of elimination here is disastrous—disabling a VLAN might isolate the issue but could disconnect critical services, introducing new failures like service outages or security breaches. The scientific method mitigates this by emphasizing non-destructive testing and evidence over intervention.
Real-world examples abound. In the 2018 AWS outage, engineers used hypothesis-driven diagnostics to trace issues to a configuration error, not by rebooting servers en masse. Similarly, network admins troubleshooting BGP hijacks rely on route analyzers and historical data, not elimination.
Wrap | Toward Smarter Troubleshooting
Relying on process of elimination in IT troubleshooting is a shortcut that often leads astray—inefficient, risky, and intellectually lazy. It's worlds apart from mathematical rigor, lacking the deductive power of negation. Instead, embrace first principles: define expected versus observed behaviors, gather evidence, and apply the scientific method. This approach not only resolves issues faster but prevents them from recurring, especially in intricate fields like computer networking.
Next time you're tempted to "turn it off and on again," pause. Ask: What do I expect? What do I know? Hypothesis, test, learn. In doing so, you'll turn troubleshooting from a curse into a craft.

Ronald Bartels | LinkedIn | Instagram